Modern Approach of Mobile App Development for a Startup Using AWS
This blog is focused on end-to-end architecture of the comprehensive solution for a specific business case and deep dive on AWS AppSync. Different AWS services such as API Gateway, Cloudfront, Lambda, Kinesis Data Firehose (KDF), Pinpoint are not discussed in detail here. It’s assumed that reader is familiar with various AWS offerings and utility at high level.
During pandemic, one of the startups came up with an idea to supply required product related to Covid illness such as Oxygen concentrator, Mask, PPE Kit, Gloves, Hydroxychloroquine (it was prescribed in US at that time to treat Covid patients), Oximeter and information regarding availability of seats in different medical facilities for covid patients. Mobile App development were in mind during realization of the idea. Timing is critical for any product development, but it adds more value in startups ecosystem. Need to transform an idea into a faster-adapting product market by accelerating release cycles. A modular approach, server-less design, pivot features rely on real-time user feedback to accelerate product success. We can easily remove parts when the architecture is no longer fit for purpose without wasting valuable time to market. This solution is driven by the best practices of modern loosely coupled, modularize microservices architecture, ‘zero trust’ security model along with benefits from serverless offerings of AWS. Architecture will provide benefits of traditional LAMP (Linux, Apache, MySQL, PHP) stack without its limitation and long-time commitment. We can divide entire architecture in 2 different layers at high level:
1.Front End
2.Data Processing and Back End Layer

Please find high level architectural walk through with the reference of mentioned number in Fig. 1:
Front End
1. AWS Amplify is the easiest way to build cloud-powered mobile and web applications on AWS. Amplify comprises a set of tools and services that enables front-end web and mobile developers to harness the power of AWS services to build innovative, feature-rich applications. The Amplify Console offers fully managed hosting with features such as instant cache invalidation and atomic deploys. We can set up a CDN and hosting buckets by using Amazon CloudFront and S3. We can choose any popular web frameworks including JavaScript, React, Angular, Vue, Next.js, and mobile platforms including Android, iOS, React Native, Ionic, Flutter.
Let me dive deep a bit on AWS Amplify in the interest of my readers who are not familiar with this offering from AWS. Below illustrations are self-explanatory from AWS documentation.
Develop

Deliver

Manage

2. User Authenticate using Amazon Cognito user pool. AWS WAF (Web Application Firewall) integration with GraphQL APIs in AWS AppSync to protect APIs against common web exploits.
Data Processing and Back End Layer
3. Managed GraphQL offering AWS Appsync is one of the key components in this part of the architecture. Organizations choose to build APIs with GraphQL because it helps them develop applications faster by giving front-end developers the ability to query multiple databases, microservices, and APIs with a single GraphQL endpoint. It’s easy to develop GraphQL API in Appsync which handles the heavy lifting of securely connecting to data sources like AWS DynamoDB, Lambda, Elasticsearch and more. Adding caches to improve performance, subscriptions to support real-time updates, and client-side data stores that keep offline clients in sync are just as easy. Once deployed, AWS AppSync automatically scales GraphQL API execution engine up and down to meet API request volumes. Authenticated clients make API calls to AppSync using valid JWT tokens generated by Cognito.
4. AppSync uses Resolvers to make direct calls to different microservices. HTTP Resolvers connect to the REST endpoints. The communication between the Resolvers and the HTTP endpoints are protected with temporary IAM credentials based on assumed IAM roles. Let’s dive deep with AWS Appsync more as it’s the heart of this architecture.
“Get exactly the data you need, nothing more, nothing less”
Above quote from Ed Lima’s re: Invent 2020 session will make sense at the end of this section. So, hold tight to start a journey with AppSync.
AWS AppSync enables developers to interact with their data by using a managed GraphQL service. GraphQL offers many benefits over traditional gateways, encourages declarative coding style, and works seamlessly with modern tools and frameworks, including React, React Native, iOS, and Android. GraphQL is a data language to enable client apps to fetch, change and subscribe to data from servers. In a GraphQL query, the client specifies how the data is to be structured when it is returned by the server. This makes it possible for the client to query only for the data it needs, in the format that it needs it in. It’s not mandatory to know GraphQL to use AWS AppSync as it can automatically setup your entire API, schema, and connect data sources with a simple UI builder that allows you to type in your data model in seconds. You can then immediately begin using the endpoint in a client application. The console also provides many samples schema and data sources for fully functioning applications.
Below illustration from re:Invent 2020 session can be helpful to explain advantages of GraphQL API over REST API. It’s self-explanatory from the illustration that number of API calls are going to be significantly less using GraphQL than REST API.
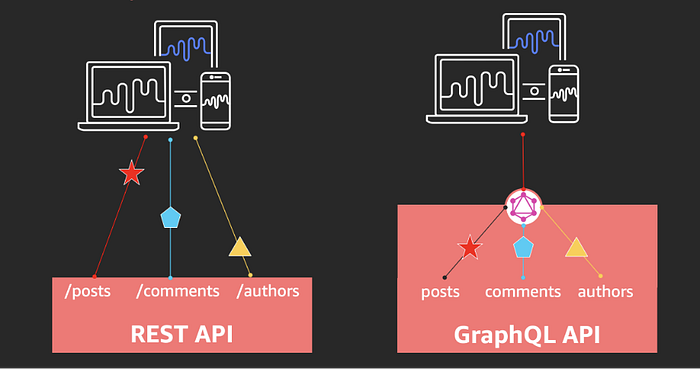
One of the most common problems with REST is that of over- and under-fetching. This happens because the only way for a client to download data is by hitting endpoints that return fixed data structures. It’s very difficult to design the API in a way that it’s able to provide clients with their exact data needs.
On the other side, GraphQL allows you to have fine-grained insights about the data that’s requested on the backend. As each client specifies exactly what information it’s interested in, it is possible to gain a deep understanding of how the available data is being used. This can for example help in evolving an API and deprecating specific fields that are not requested by any clients anymore. So, now it may make sense of the quote “ Get exactly the data you need, nothing more, nothing less” from beginning of AppSync section in this blog.
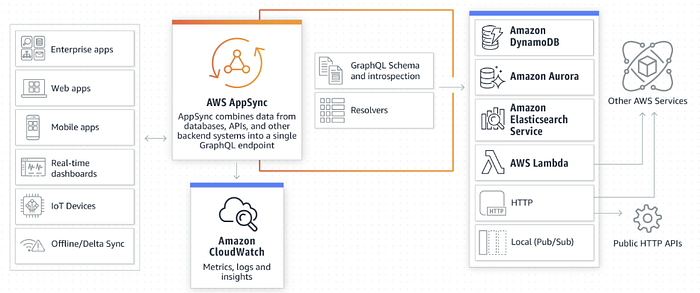
Above figure Fig 6 from AWS documentation provide working principle in a nutshell. In AWS AppSync, A GraphQL schema is a definition of what data capabilities are available for the client application to operate on. For example, a schema might say what queries are available or how an app can subscribe to data without needing to know about the underlying data source. Schemas are defined by a type system, which an application’s data model can leverage. Resolver is a function that converts the GraphQL payload to the underlying storage system protocol and executes if the caller is authorized to invoke it. Resolvers are comprised of request and response mapping templates, which contain transformation and execution logic.
5. AWS Kinesis Firehose (KDF) is connected through AWS SDK API from Lambda function. KDF is used to capture stream of request in S3 and AWS Lambda is used in conjunction to convert the file into columnar format Parquet. Near real time anomaly detection can be done using lambda with KDF and push notification through outbound and inbound marketing communications service Amazon Pinpoint.
6. AWS Lambda function is split into two functions based on each Update and Delete operation. Internal routing logic is now decoupled from business logic. The API Gateway service uses rules to route requests to the appropriate Lambda function. This allows each feature to scale independently, and updates can be made to one feature without affecting another. Each Lambda function has limited scope and minimal business logic. It can use lightweight custom-built PHP runtime to reuse code from existing LAMP stack. We can develop different microservices independently using different technology such as various runtime in Lambda. This will help to reduce blast radius in case of failure with a particular service.
7. The GraphQL microservice returns information with defined busines logic by another AppSync API connecting to storage services such as DynamoDB, RDS or Elasticsearch.
8. Another service (or group of microservices) is hosted on serverless AWS Fargate containers in a private VPC and returns information for the user. One of the reasons for using serverless offering such as Fargate here due to unpredictable nature of the load and low maintainability as startup can focus more on their business value rather than spending more time to manager infrastructure.
9. Amazon Elastic Container Registry (ECR) uses Amazon S3 for storage to make container images highly available and accessible, allowing to reliably deploy new containers for applications.
10. Serverless database offering Amazon Aurora Serverless (MySQL), NoSQL database Amazon DynamoDB is used to meet uncertain demand with optimize pricing.
11. DynamoDB stream trigger lambda function with any changes in data and that push data synchronously into high performing AWS managed open-source distributed search and analytics service Amazon Elasticsearch.
12. AWS Code Pipeline with AWS CodeBuild, AWS Code Commit (14) can provide feature for end-to-end build and release. Using pipeline, Docker Image can be built for pushing to ECR and from there image can be deployed to Fargate as a part of Continuous Integration, Continuous Deployment (CICD) process.
13. Amazon Pinpoint is built to scale, enabling architecture to collect and process billions of events per day, and send billions of targeted messages to the users. We can view analytics data on the Amazon Pinpoint console. The console provides detailed charts and metrics that provide insight into areas such as customer demographics, application usage, purchase activity, and delivery and engagement rates for campaigns.
14. Scheduled Lambda would invoke Glacier multipart upload API through AWS SDK to upload inactive objects greater than 6 months into cold storage offering AWS Glacier.
Now, I would like to discuss technical and business value of the solution after providing technical walkthrough of the end-to-end architecture.
Business and Technical Value Addition
· Scaling to Meet Uncertain Demand — This serverless (Appsync, Lambda, API Gateway, DynamoDB, Aurora Serverless, Fargate, Kinesis Data Firehose) heavy solution can easily scale up and down with changing load.
· Disaster Recovery — The AWS global infrastructure is built around AWS Regions and Availability Zones. This architecture is designed and operate applications and databases that automatically failover between zones without interruption. All data is captured in S3. Periodic snapshot or Point-in-time recovery (Aurora Serverless, DynamoDB) is being enabled according to Recovery Point Objective (RPO).
· User identities & Sync user specific data across Device — Amazon Cognito Sync is an AWS service and client library that enables cross-device syncing of application-related user data. Amazon Cognito with AppSync user data like app preferences or game state to be synchronized. It also extends these capabilities by allowing multiple users to synchronize and collaborate in real time on shared data.
· Push Notification — Mobile application in client side needs to set up as that it receives push notifications that send by using Amazon Pinpoint.
· Application Analytics — Amazon Pinpoint offers several types of standard analytics that provide insight into how application is performing. Standard analytics include metrics for active users, user activities and demographics, sessions, user retention, campaign efficacy, and transactional messages. Usage data stored in S3 can be useful to do more analytics using third party dashboarding tool or Amazon Quicksight.
· High Performance and Throughput Data Access Layer –AWS RDS is a managed relational database service. It’s extremely easy to run and manage database with. On top of that Aurora serverless makes operational teams free from database scaling activities by changing instance type, Size or creating read replica. Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. DynamoDB support applications with virtually unlimited throughput. Amazon RDS Proxy can handle many connections in a manageable way.
· Self-healing infrastructure — Amazon Elasticsearch provisions all the resources for Elasticsearch cluster and launches it. It also automatically detects and replaces failed Elasticsearch nodes, reducing the overhead associated with self-managed infrastructures. Rest of the serverless services are self-healing as out of the box offerings.
· Security — “zero trust” security model is used in this microservice based architecture to secure micro-perimeters around each resource. AWS Identity and Access Management (IAM) resource policies and execution roles to decouple business logic from security posture. Lambda resource policies define the events and services that are authorized to invoke the function. Lambda execution roles place constraints the resource or service the Lambda function has access to.
· Loosely Coupled Environment Access — Required infrastructure for this entire proposed architecture can be converted in to code using AWS CloudFormation. AWS Amplify makes it easier to handle multiple environment and team.
· Archival strategy — Scheduled lambda would check inactive object from last 6 months in all S3 object and upload those into Glacier archive. AWS Data Migration Service (DMS) can be used to load inactive data from RDS Aurora to S3 and then trigger event-driven lambda with Glacier archival API. TTL (Time-to-Live) property of DynamoDB with custom function of can push inactive data into S3.
References:
System Overview and Architecture
System Overview and Architecture for AWS AppSync.
docs.aws.amazon.com
https://aws.amazon.com/blogs/mobile/aws-appsync-offline-reference-architecture/